我校中医药创新研究院/交叉学科研究院本草基因组学研究团队在表型导向的药物发现研究领域取得重要突破,成功开发出融合化合物剂量、扰动时长与细胞系特异性的深度学习模型DeepICER,其可预测任意剂量、时长及细胞系中化合物扰动引起的特征基因表达谱变化,为高效药物筛选和作用机制研究提供了强有力的计算工具。相关研究成果以“DeepICER: A Deep Learning Framework for Predicting Compound-Induced Gene Expression Profiles”为题,发表于《Acta Pharmaceutica Sinica B》(中科院一区,TOP期刊)。我校孟繁博特聘副教授为论文第一作者,冷梁副教授和陈伟教授为共同通讯作者。

基因表达谱是解析细胞功能状态、挖掘疾病潜在机制的核心指标,也是表型导向药物发现的重要依据。高通量测序技术的快速发展及公共数据库的完善,为基因表达谱研究提供了坚实的数据基础。然而,药物分子结构的复杂性、细胞系的多样性,以及剂量与扰动时间等实验条件的多变性,使传统实验方法难以系统探索所有化合物扰动效应。同时,现有深度学习模型大多无法有效整合剂量和时长等关键参数,并存在细胞类型特异性区分能力不足、跨细胞系泛化能力有限等问题,严重制约了其在药物研发中的实际应用。因此,开发能够融合多维信息的化合物诱导基因表达谱预测模型,成为推进药物发现与药物重定位研究的迫切需求。
针对上述难题,研究团队创新性构建了DeepICER模型,该模型整合化合物结构、剂量、扰动时长及细胞系类型等因素,采用四模块协同架构实现了基因表达谱预测。化合物编码模块将剂量与扰动时长信息嵌入分子图原子节点特征,通过图卷积网络学习协同表征;细胞系编码模块结合基因本体注释与表达值构建融合矩阵,经一维卷积网络提取特异性细胞系特征;双线性注意力网络模块精准捕捉化合物与细胞系特征间的复杂相互作用,同时提升模型可解释性;预测模块通过全连接网络高效输出标志性基因表达谱。基于 CMap 核心假设,团队还为 DeepICER 构建了“预测–评分–筛选”的完整应用流程,实现了候选化合物的快速筛选与评估。
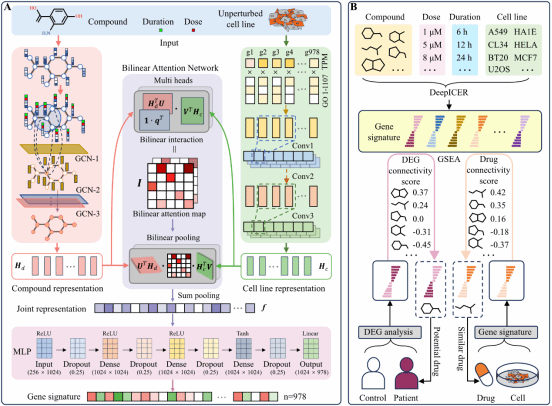
性能评估结果显示,DeepICER在测试集上的平均Pearson相关系数达0.729、Spearman相关系数为0.703,相较于DeepCE、MultiDCP等现有先进模型,Pearson相关系数提升45.1%、均方误差降低60.82%,且在未见化合物、未见细胞系、未见剂量、未见时长等挑战性场景下仍保持稳健性能,展现出极强的泛化能力。实验验证表明,DeepICER能准确识别并复现肺腺癌已批准治疗药物的转录组特征,后续针对肺腺癌的新药筛选中,从6389种化合物中成功筛选出PD-166285等候选化合物,细胞实验证实PD-166285对A549细胞的抑制效果优于紫杉醇,充分验证了模型预测的生物学一致性与实际应用价值。
研究团队基于 DeepICER 生成了超过 1800 万条扰动表达谱,涵盖 FDA 批准药物、BROAD 重定位化合物及天然化合物三大化合物库,涉及 80 种细胞系,并覆盖多组剂量与扰动时长条件。同时,团队开发了免费在线平台(https://cbcb.cdutcm.edu.cn/deepicer/),支持化合物扰动表达谱预测、评分计算及药物重定位分析,科研人员可通过输入化合物SMILES、特征基因表达谱等信息快速获取分析结果。
DeepICER通过其创新性的多因素整合模型设计、卓越且稳健的预测性能,以及配套的大规模数据资源与便捷的在线平台,有效突破了现有模型在灵活性、准确性及实用性方面的局限。该框架为药物重定位、药物作用机制解析以及新型治疗候选分子的高效发现提供了强大的技术支撑,有望显著加速表型导向的药物研发进程。
该研究得到国家自然科学基金(32470710)、四川省揭榜挂帅项目(2024ZDZX0019)和成都中医药大学“杏林学者”学科人才科研提升计划(MPRC2021036)的支持。
全文链接:https://doi.org/10.1016/j.apsb.2026.01.046
(文、图/中医药创新研究院/交叉学科研究院)


